De Bruijn Sequences
- Reed Nelson
- May 5, 2021
- 20 mins
- Mathematics
- graph math
De Bruijn sequences are named after Nicolaas Govert de Bruijn, a Dutch mathematician who wrote about them in his 1946 paper A Combinatorial Problem1. The idea, however, dates back to at least the 19th century.
We will begin by exploring some of the interesting combinatorial and graph theoretical properties of de Bruijn sequences. With these in mind, we’ll discuss an algorithm which generates all de Bruijn sequences for a given alphabet and window size (these parameters will make sense shortly). Then we’ll look at shuffling-related properties, and a few of the applications for these sequences.
Properties
Let be an alphabet of distinct characters2. A de Bruijn sequence is a cyclic string of characters from where each permutation of characters appears exactly once. will be used to denote the set of de Bruijn sequences of window length and alphabet length .
Property 1: The length of a sequence is .
Proof: The number of n-permutations of k characters is , and given by the definition, each of those permutations must appear exactly once. Take to be a minimum-length sequence of length consisting of all unique permutations in question. In each window length n sits one permutation. If the window is shifted over one character, this must give another unique permutation. Thus the smallest possible value of would be . Suppose . Then the number of windows in would be greater than , and thus would contain non-unique permutations, and would not be a de Bruijn sequence. Therefore, the length of a sequence is .
Property 2: The number of distinct sequences equals . Because de Bruijn sequences are cyclic, we consider mere rotations of one sequence to be the same, non-distinct, sequence. For example, 3 has 2 distinct sequences of 8 characters: , and . We could rotate the first sequence 3 to the right, yielding , but none of the 8 rotations would result in the second sequence.
De Bruijn Graphs
Each has a corresponding de Bruijn graph. The example in the figure below shows the graph for .
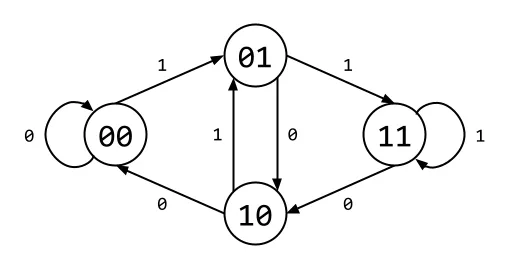
De Bruijn graphs are directed Eulerian graphs, which is to say that there exists a circuit (connected loop) within the graph which visits each edge exactly once. These graphs have a number of interrelated properties.
Property 3: For all vertices of , the number of edges pointing in toward the vertex (in-degree) equals the the number of edges pointing away from the vertex (out-degree), which is also equal to the size of the alphabet (). This implies that for all , each vertex has an even degree, which is consistent with the (cool) fact that a connected graph has an Eulerian circuit if and only if each vertex has an even degree.
Property 4: Each vertex represents a unique permutation of characters from , and of course, all permutations are represented. From this, it follows that the graph for is of order .
Property 5: Each outgoing edge from each vertex is labeled with a different character . Then any two of the following can be used to determine the label of the third: 2 adjacent vertices and their single adjoining edge. For example: the label of the vertex a particular edge points to can be determined by removing the leftmost character from the outgoing vertex, and appending to it the edge’s label . This is equivalent to shifting the window of a de Bruijn sequence right one character, and that new character being .
Property 6: Because each vertex has exactly incoming and outgoing edges, the number of edges of are , or . Notice that has a number of vertices equal to the number of edges of . We can draw the graph for in the following way: put a vertex where each edge of would be, whose label is the character on that edge, concatenated to the source vertex. In this way, each vertex remains unique with respect to all other vertices in the graph. Applying this method to the graph pictured above yields the graph pictured in the figure below. This tracks with Property 4.
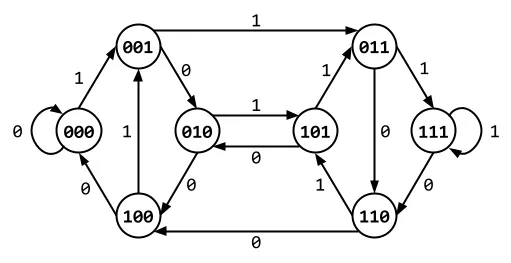
Property 7: By following an Eulerian circuit through a graph, and recording the label of each edge as it is visited, one gets a sequence. Furthermore, the set of sequences constructed by taking all Eulerian circuits in the graph is identical to the set of sequences. This fact is key in creating a generating algorithm.
Property 8: An Eulerian traversal of a de Bruijn graph is a circuit.
Proof: The in-degree of each edge of a de Bruijn graph equals its out-degree (Property 3). Let be the start vertex of the Eulerian traversal. For to have been traversed to, on each occasion, it must have first been traversed away from. Thus, once all incoming edges to have been traversed, the outgoing edges necessarily have also been traversed. Therefore, if it is not the case that an incoming edge to is the final edge to be traversed (making the traversal a circuit), then the traversal cannot be Eulerian.
A Generating Algorithm
The following method will generate all de Bruijn sequences of for given values of and in two parts: first, generate the corresponding de Bruijn graph; second, traverse through it in all ways which visit each edge exactly once.
Constructing the Graph
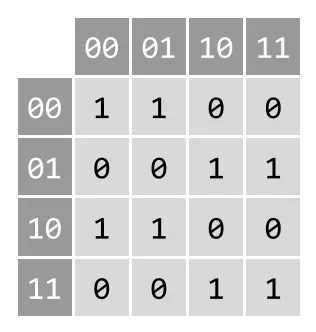
The graph will be represented by an adjacency matrix4. The data structure of choice will be a 2-dimensional array , for . This choice gives a space complexity of , which is generally unideal for sparse graphs, however we should expect time complexity to be a vastly larger bottleneck for most values of n and k. This choice gives a time complexity for accessing any element of the matrix of .
Each vertex (a value in base-) corresponds to the index of that value in decimal. Then whether one vertex points to another (or the same) depends on if the rightmost characters of the row index are the same as the leftmost characters of the column index (in the spirit of the example described in Property 5). The adjacency matrix corresponding to the graph is pictured in the figure below, and can be verified by examining the first figure.
Traversing the Graph
From properties 7 and 8, we know that finding all sequences is equivalent to finding all distinct traversals of the graph which visit each edge once. This will be implemented by recursively traversing through the graph and identifying all traversals which meet that criterion, (a sort of depth-first search). Each time a vertex is reached, there are two cases to consider:
- The vertex has non-traversed outgoing edges. Then the edge with the label of lowest numerical value is followed, that edge is noted as visited, and it’s label is appended to a list.
- The vertex has no non-traversed outgoing edges. Then, if the list is length , an Eulerian circuit has been completed, and the list is a de Bruijn sequence, so it is stored. If the list is less than length , that traversal did not complete an Eulerian circuit and the list is not stored. In either case, the rightmost character is truncated from the list, and the vertex in question returns to the previously visited one.
This algorithm terminates when all paths in the graph have been traversed. Implementation involves the use of some additional data structures. A boolean matrix can be used to keep track of whether an edge has yet been traversed, allowing for access. Something like a stack data structure could to be used to store the values of the edges which have been traversed, as this allows for pushing to and popping from the list.
Additional Notes
In practice, this algorithm’s biggest bottleneck is neither time nor space complexity (in runtime). The problem is about the volume of data output. These sequences grow in number and length extraordinarily fast (recall Properties 2.1 and 2.2). At 1 byte/character, a file containing all sequences would be 4 GB in size. A file containing all sequences would be 65,000,000,000 GB. Changing the alphabet makes for even more radical growth. A single sequence would be 10 GB. What’s more, these files would be highly incompressible due to the nature of the character distribution. Read this post to learn more about data compression.
Shuffling Binary Sequences
Shuffling
My original motivation for exploring de Bruijn sequences was related to card magic, so to that end, let’s examine binary de Bruijn sequences which have the property that, after undergoing a perfect shuffle, retain their original order. For brevity, we will say a binary de Bruijn sequence shuffles if and only if it has this property. In this section, a perfect shuffle5 refers to a perfect in-shuffle or a perfect out-shuffle. Let’s see how these are performed.
Let be the length of a sequence, and denote the index of each element in the sequence, for .
An in-shuffle reorders the elements of the sequence according to the rule:
An out-shuffle reorders the elements of the sequence according to the rule:
An example of an in-shuffle:
An example of an out-shuffle:
Properties
Property 9: For arbitrary , not all sequences shuffle.6
Property 10: Of sequences that shuffle, only certain rotations do.
Below are some results from a function which checks each rotation of each sequence provided by the generator, and returns those which out-shuffle.

There would be a number of interesting directions to take this shuffling idea. The naive method for checking if a sequence can shuffle to itself would be with respect to the length of the sequence: for each of rotations, you compare the character at each index of the original sequence to the character at each index of the transformed sequence. I wonder if it’s possible to tell whether some rotation of a sequnce will shuffle, just by examining a single rotation. One might also be able to take this in an algebraic direction: perhaps the right sets of sequences shuffle to each other, forming a group under shuffling operation.
Applications
De Bruijn sequences have applications in a diverse set of areas. Most notable among them may be gene sequencing in the field of genomics. The basic idea is that codons can be thought of as characters in the alphabet , and a de Bruijn sequence constructed from them provides an efficient, redundancy-free series of coding sequences.7
Another interesting application is in (especially self working8) card magic. For example, one might leverage the binary color options to order the deck in a de Bruijn sequence. The spectator then draws n consecutive cards and recites their colors, on order. With this information and a bit of memorization ahead of time, the performer is able to identify exactly where in the sequence the spectator drew from, and thus what the values of their cards are. A strength of this trick is that one can cut the deck ad infinitum without ever breaking the sequence. I think it would be possible to strengthen this type of trick by leveraging properties of certain sequences that shuffle. I can see only two obstacles here: First, sequences that shuffle are relatievely rare, and there are further constraints given a standard deck’s color/suit/value system, and the size of the sequence. Second, executing a perfect shuffle is just a difficult thing to do. But these challenges are very surmountable.
As far as other applications, de Bruijn sequences have been used in fMRI research, bit operations in Computer Science, and even in cracking PIN locks which accept rolling input. There are others, but none appear to be too grand or significant. The diversity of applications is perhaps more notable than the applications themselves.
I have wondered about the possibility of a cryptographic application, but my intuition says this path is fruitless. In short, it’s usually very valuable to have a large space of posible values, both to use as keys and to encode data, so I would be skeptical that any benefit de Bruijn sequences might bring would outweigh the cost of a greatly reduced possibility space.
Closing Thoughts
De Bruijn sequences and graphs have many interesting and simple properties. This fact allowed me to extend my study beyond the existing literature and into a more exploratory domain. In fact, I might have identified several properties unstated in any literature on this subject. As far as I can tell, even the generating algorithm is novel. But of course, there has been very little work done in this area beyond de Bruijn’s original paper, and most mathematicians probably had the forethought to know there is no reason why anyone would need every sequence in a given alphabet and window.
I wrote a Java implementation of the generating algorithm and shuffles described above, along with a suite of other tools pertaining to de Bruijn sequences and graphs. This code and select output files from the generating function can be found here.
Footnotes
-
Nicolaas Govert de Bruijn, A combinatorial Problem (1946). ↩
-
A binary alphabet is often implied with de Bruijn sequences, but most of what this paper discusses is applicable to an arbitrary alphabet. ↩
-
The nominal values of the characters used in the alphabet are unimportant, so for this paper and generally, when , we take . ↩
-
An adjacency matrix is a boolean-valued by matrix where the indices of the rows and columns correspond to the vertices in the graph, and the truth-value at a coordinate depends on the existence of an edge from vertex to vertex . ↩
-
Concerning playing cards, a perfect shuffle (in or out) corresponds to a perfect Faro shuffle. In practice, it would take much skill to reliably execute the Faro shuffle perfectly. ↩
-
It would be interesting to prove that for all n, there exists a sequence that shuffles. ↩
-
See A novel codon-based de Bruijn graph algorithm for gene construction from unassembled transcriptomes (2016). Available here. ↩
-
A self working trick refers to one which follows a fixed procedure that does not depend on circumstance or skill. ↩